Artificial Intelligence (AI) has made tremendous strides in many areas, but one of its most significant challenges has been understanding human language. Machines and systems that can accurately interpret language are essential for improving our interaction with technology. Imagine asking a voice assistant like Siri or Google Assistant a complex question and receiving an irrelevant response. That’s where Natural Language Processing (NLP) comes into play.
What is Natural Language Processing?
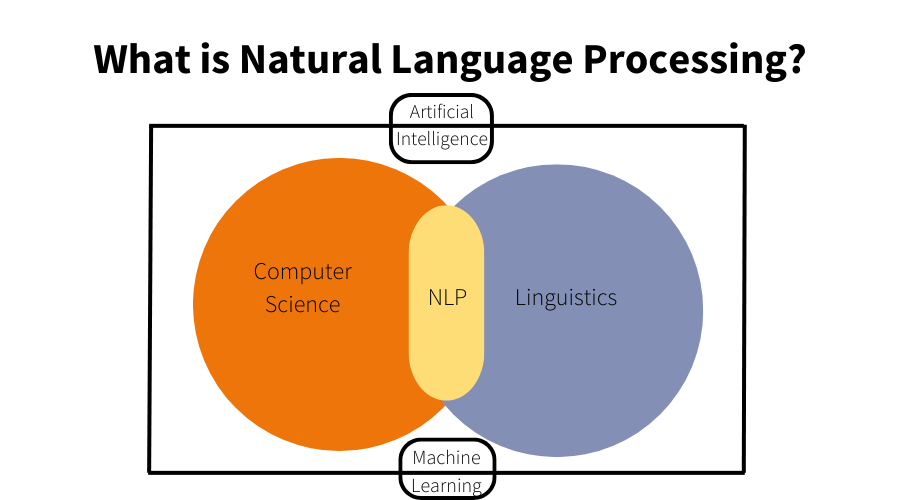
NLP is the technology behind teaching machines to understand, interpret, and generate human language in a useful way. The better these systems understand our questions, the better they can answer our queries. However, language is inherently complicated—words can have different meanings based on context, sentences can be long and detailed, and human communication is often ambiguous. NLP models attempt to decode this complexity, helping search engines, voice assistants, chatbots, and other AI systems provide more accurate and meaningful results.
But even with advances in machine learning and NLP, there were limitations, particularly with understanding context. That’s where BERT comes in. BERT changed the scope for NLP, enabling AI models to grasp the context of words in a sentence in a way that’s much closer to how humans understand language.
How BERT Revolutionised NLP?
Before BERT, many search engines and NLP models struggled with understanding the nuances of language. For example, they would often miss context when processing a query, focusing on individual keywords rather than understanding the sentence as a whole. This approach led to less accurate results, as the models weren’t fully interpreting what users were asking.
Then came BERT (Bidirectional Encoder Representations from Transformers), which turned the world of NLP upside down. Released by Google in 2018, BERT helped search engines better understand the intent behind search queries. Instead of treating words as isolated units, BERT processes a word in the context of all other words in a sentence. This allowed Google to deliver search results that are more accurate, meaningful, and aligned with the user’s true intention.
With BERT, Google made a critical advancement in natural language understanding through the algorithm update. Its ability to understand and interpret words in relation to their surrounding context meant that search engines could better comprehend even the most complex, conversational queries.
What Does BERT Stand For?
BERT stands for Bidirectional Encoder Representations from Transformers, and it’s a mouthful, but breaking it down simplifies it:
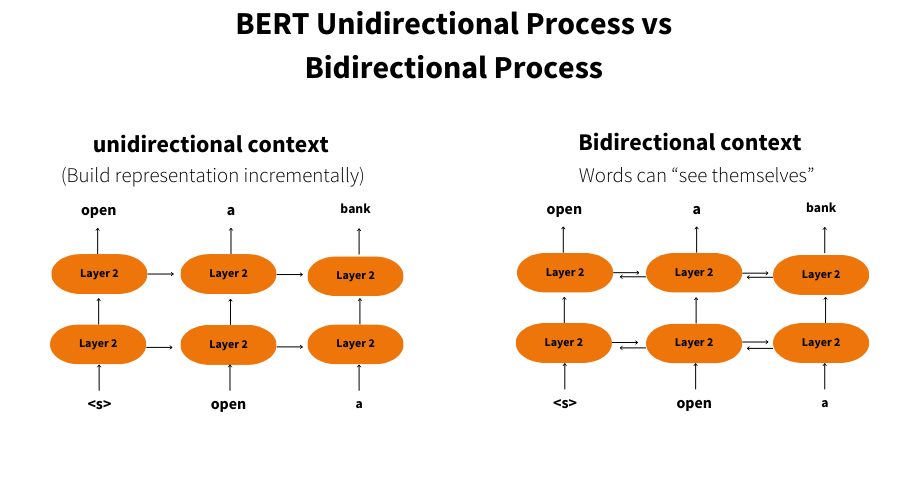
Bidirectional: Unlike earlier NLP models that processed language one word at a time (from left to right or right to left), BERT reads the entire sentence in both directions. This “bidirectional” processing allows it to better capture context.
Encoder Representations: Encoders help convert words into representations that machines can understand. BERT creates more nuanced representations of words based on the words around them.
Transformers: Transformers are a type of architecture in machine learning that is particularly helpful for understanding long-term dependencies in language. BERT leverages this to keep track of relationships between words over the course of a sentence.
What sets BERT apart from previous models is its deep bidirectional training. By considering both the left and right context of a word, BERT can understand words in a way that’s much closer to how humans do. This ability to fully grasp the meaning of a word based on the entire sentence is a huge leap forward for language models.
How BERT Was Introduced?
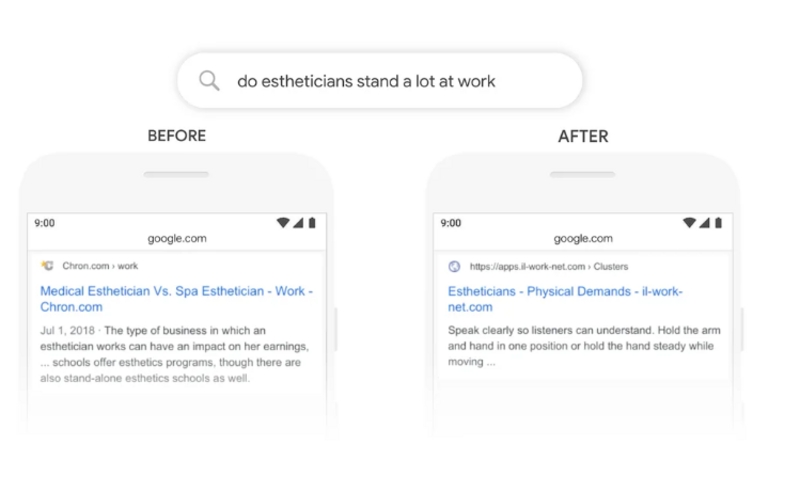
Google implemented BERT into its search algorithm in 2018, marking one of the most significant improvements in search technology. Previously, search engines used simpler keyword-based algorithms, which often missed the context of a user’s query. For instance, pre-BERT, if someone searched for “train to cook a turkey”, the model might confuse “train” as a mode of transportation rather than a method of learning. With BERT, search engines became much better at understanding the entire phrase.
BERT’s introduction to Google Search brought about a 10% improvement in the accuracy of search results. This might not sound massive, but in the world of search, where even small improvements can mean billions of better user experiences, it was revolutionary. People started receiving more relevant search results, especially for long, conversational, and complex queries.
Understanding how BERT works requires diving into some of the more technical aspects of machine learning and NLP. But don’t worry, we’ll break it down into smaller parts.
Transformers
At the core of BERT’s architecture is something called a Transformer. Transformers are neural network architectures that are exceptionally good at handling long sequences of data, which is crucial when you’re dealing with human language. Instead of processing one word at a time, a Transformer can look at the whole sentence simultaneously and determine which words are important to each other.
For example, in the sentence, “The cat sat on the mat,” a Transformer would understand that “cat” and “mat” are linked, and that “on” establishes the relationship between them. This means it can focus on different parts of the sentence based on their importance, helping it learn the structure and meaning of the text.
Transformers were a key innovation because previous models struggled to keep track of relationships between words over longer texts. BERT’s ability to track these relationships bidirectionally (both left-to-right and right-to-left) is a major factor in its success.
Masked Language Modeling
One of BERT’s most innovative features is Masked Language Modeling (MLM). In traditional language models, words are predicted based on their surrounding words in a left-to-right fashion. For instance, given the sequence “I want to go to the _____”, the model might predict “store” or “beach” based on the previous context.
However, BERT takes a different approach. During training, it randomly masks (hides) certain words in a sentence, and the task is to predict the masked word based on the surrounding context. For example:
Input: “The cat [MASK] on the mat.”
BERT has to predict that “[MASK]” is “sat” by considering the other words in the sentence.
This approach helps BERT better understand context and meaning because it forces the model to look at the entire sentence, not just part of it.
Self-Attention Mechanisms
BERT’s self-attention mechanism is another crucial component. It allows BERT to weigh the importance of different words in a sentence when determining their meaning. For example, in the sentence “The car drove fast because it was late,” BERT can understand that “it” refers to “the car” by paying attention to the relationship between these words.
In essence, self-attention gives BERT the ability to focus on the most relevant parts of a sentence and understand which words relate to each other. This is essential for understanding more complex or nuanced queries.
Next Sentence Prediction
In addition to predicting individual masked words, BERT also tackles Next Sentence Prediction (NSP). This helps the model determine if two sentences logically follow each other. For instance, if you give BERT the sentence “I bought a new phone,” and then ask it to predict if “The camera quality is excellent” logically follows, it will make a prediction based on context.
This feature is crucial for tasks like question-answering and dialogue systems, where understanding how sentences relate to each other is essential. By training BERT on this task, it becomes more adept at interpreting longer texts and conversations, improving its ability to understand context and meaning in a more comprehensive way.
What is BERT Used For?
One of the most widely recognised uses of BERT is in improving search engine results. Google first integrated BERT into its search engine in late 2018, and it had an immediate and measurable impact. Search engines have evolved significantly over the years, moving from basic keyword matching to more sophisticated algorithms that attempt to understand user intent. However, they still often struggled with complex or conversational queries before BERT came along.
BERT’s bidirectional training allows it to understand words in the context of the entire sentence, which is especially useful for Google search, where users often type in long and ambiguous queries. For example, a search like “Can you get medicine for someone pharmacy” previously may have returned less relevant results because of the complexity of the sentence. With BERT, Google is better able to discern that the user is asking whether they can pick up a prescription for someone else at the pharmacy.
Additionally, BERT improved the understanding of prepositions like “for” and “to,” which can drastically change the meaning of a search query. By understanding these subtle nuances, BERT helps ensure that the search results provided are closer to the user’s intent.
Some key improvements BERT brought to Google search include:
Improved query comprehension: Better understanding of long, conversational queries where context is essential.
Natural language understanding: Enhanced interpretation of natural language, making search results more aligned with everyday speech patterns.
Understanding polysemy: Better differentiation of words with multiple meanings based on context (e.g., “apple” as a fruit vs. the tech company).
An Overview of BERT Architecture
The BERT model stands out for its unique bidirectional approach to understanding language. Let’s take a closer look at some of the key components that make up BERT’s architecture.
Bidirectional Understanding
One of the key differentiators of BERT’s architecture is its bidirectional nature. Most previous NLP models, including older Transformers, processed text in a single direction, either from left to right or from right to left. This meant that these models only had a partial understanding of the context. For example, if the model was processing the sentence “The teacher helped the student because she was struggling,” older models might struggle to figure out who “she” refers to, as they only process one part of the sentence at a time.
BERT, on the other hand, processes the sentence from both directions, considering all the words at once. This means it can be understood that “she” refers to “the student” by considering the surrounding context on both sides of the word. The bidirectional nature of BERT allows it to have a fuller understanding of context, which is why it performs so well on tasks that require a deep understanding of language.
Training with Large Datasets
BERT is pre-trained on massive datasets to learn language patterns before it is fine-tuned on specific tasks. During pre-training, it is exposed to vast amounts of text data, such as the entire English Wikipedia (over 2.5 billion words) and the BookCorpus dataset, which consists of 11,000 books. This large-scale pre-training allows BERT to learn common language patterns and structures that it can apply to various NLP tasks.
After pre-training, BERT is fine-tuned for specific downstream tasks, such as question answering, sentiment analysis, or text classification. This fine-tuning allows BERT to adapt to the specific requirements of different use cases. The combination of large-scale pre-training and task-specific fine-tuning makes BERT incredibly versatile and powerful across a wide range of applications.
Importance of Need BERT
Before BERT, most NLP models were limited in their ability to understand complex language structures. Many early models used RNNs (Recurrent Neural Networks) or LSTMs (Long Short-Term Memory), which processed words one by one in a sequential manner. This unidirectional approach made it difficult for the models to fully capture context, especially in longer sentences.
One common issue with these models was their inability to capture long-range dependencies in a sentence. For instance, in a long sentence, the model might forget the meaning of earlier words by the time it reaches the end. This led to poor context understanding and less accurate results.
Additionally, many of these models struggled with tasks where understanding the relationship between different parts of a sentence was essential. For example, in tasks like reading comprehension, the model needed to understand how different parts of the text were related to answer questions correctly. This is where BERT’s innovations came in to solve these problems.
The Growing Need for Human-Like Understanding in AI
As AI becomes more integrated into everyday life, there’s a growing need for systems that understand language in a way that closely mirrors human understanding. Whether it’s a voice assistant, a search engine, or a customer service chatbot, users expect these systems to comprehend their queries accurately and provide relevant responses.
BERT helps meet this need by providing a model that understands the subtleties and nuances of human language. With BERT, AI systems are no longer limited to keyword matching or simplistic interpretations. They can handle complex, conversational queries, grasping the full meaning of a sentence and responding in a way that feels more human-like.
Impact on Generative AI
Although BERT itself is not a generative model, its foundational technology has influenced the development of generative AI models like GPT (Generative Pre-trained Transformer). While GPT models are trained to generate text, BERT’s innovations in language understanding have contributed to advancements in how these generative models process and interpret language.
The future of NLP is likely to see further integrations between models like BERT and generative AI, as researchers continue to push the boundaries of what AI systems can achieve in understanding and producing human-like language.
Get Expert Guidance from Loop Digital
We hope this article has given you a clear understanding of BERT and its pivotal role in revolutionising Natural Language Processing. From its ability to understand context better than any previous model to transforming search engine results and driving innovation across industries, BERT is undeniably a game-changer in the digital world.
Thank you for taking the time to read our blog post. We hope you found it insightful and helpful. If you’re looking to leverage the power of advanced AI models like BERT in your digital marketing strategy, Loop Digital is here to guide you. Whether you want to improve your website’s SEO, boost your search rankings, or gain more visibility for your content, our team of experts can help.Don’t miss out on the latest trends and tips in digital marketing—subscribe to our mailing list to stay updated. If you’re ready to take your business to the next level, why not schedule a free consultation with us today? Together, we can discuss how Loop Digital can support your growth and bring your digital marketing strategy to life!
Emir is an invaluable member of our team, serving as one of our esteemed Account Managers. With a profound passion for on-page SEO, he possesses an exceptional talent for discovering innovative ways to optimise websites and enhance their rankings. Joining our organisation, Loop, in 2022, Emir brought with him a wealth of expertise gained from his Bachelor's degree in Marketing Management and Advertising. Currently, he is eagerly pursuing his Master's degree in International Marketing Strategy, further enhancing his comprehensive understanding of the global marketing landscape. Emir thrives on challenges and continuously seeks fresh opportunities to elevate our clients' businesses to new heights. Aside from his professional endeavours, Emir has an unwavering passion for culinary arts and loves to cook up a storm. This ardour for cooking exemplifies his drive, creativity, and meticulous attention to detail, qualities that seamlessly translate into his work as a Digital Marketing Executive. His commitment to delivering exceptional results and his genuine enthusiasm for each project make him a trusted and highly sought-after professional. Emir's profound expertise in on-page SEO, combined with his ambitious pursuit of knowledge and dedication to his clients, make him an invaluable asset to our team. His passion, both in and out of the office, reflects his commitment to excellence, leaving an indelible mark on our clients' businesses.
Looking for your next opportunity?
Digital marketing careers
We’re always on the lookout for talented individuals to join our ever growing team. If you think you’d be a great match for Loop Digital, we’d love to hear from you.